Revisiting GPT-1: The spark that ignited the fire of LLMs
Revisiting GPT-1: The spark that ignited the fire of LLMs
A Comprehensive Look at GPT-1's Contribution to the Development of Modern LLMs

While folks are debating whether the yet-to-be-released Llama-3-405B can match GPT-4, and others are waiting for GPT-(4.)5 - I thought it would be a great idea to revisit the spark the started it all: the OG GPT-1 model by OpenAI.
In fact, the GPT-1 recipe is very similar to today’s state-of-the-art approaches to the degree that Mistral-7B is basically a scaled up version of GPT-1. It has stood the test of time quite well over 6 years, a marvelous feat in machine learning!

Background: The Bottleneck of Deep Learning
Deep learning has revolutionized the field of artificial intelligence in the early 2010s, with significant advancements in areas such as computer vision and natural language processing. However, one of the major challenges in this field is the immense requirement for vast amounts of high-quality, human-annotated datasets. These datasets are essential for training large neural networks through supervised learning, where the model learns by comparing its output to the desired output provided by human annotators.
The reliance on human-annotated data presents a significant bottleneck, especially in low-resource domains where acquiring large amounts of annotated data is challenging. The process of annotation is not only costly and time-consuming but also prone to errors, making it a less-than-ideal solution. As any researcher or practitioner in this field knows, the expense of human annotation far surpasses that of even the most high-end GPUs!
Clearly, there are huge wins to be made if we can eliminate or even reduce the need for human annotation.
Unsupervised Pretraining to The Rescue
Unsupervised pre-training emerged as a potential solution to the data labeling problem. Instead of relying on human annotation to teach languages to machines, what if we can leverage linguistic information from unlabeled data? This would alleviate the need for large amounts of labeled data.
Even if we have lots of labeled data, using unsupervised learning to learn good representations provides a significant performance boost. This approach is known as transfer learning. This approach has been utilized extensively in computer vision where CNNs (e.g. ResNets) are first trained for a specific task on a large dataset (e.g. classifying images in ImageNet) and then used as a backbone for downstream, unrelated tasks like object detection.
In this context, “unsupervised learning” means not requiring human annotated data. This doesn’t mean that the model is not supervised in training; the model is still learns by giving it the input and the desired output. One way to do this is causal language modeling on unlabeled corpus. Here, we are training the model to predict the next token in a sequence. A better name for this approach is self-supervised learning where we can bootstrap the labels “correct answer” from the data itself instead of relying on an external source for labels such as human annotators.
This is inherently different from true unsupervised learning technique such as clustering and dimensionality reduction where there is no label at all; there is no “correct answer”, and the goal is often to uncover underlying patterns or structures in the data.
Transfer Learning in NLP
There is extensive evidence of the effectiveness of transfer learning in NLP. Researchers have achieved state of the art performance on many tasks by utilizing pre-trained word embeddings as input features to a task-specific head. These tasks include dependency parsing, sentence classification and machine translation.
Word Embeddings
The concept of word embeddings was popularized in Word2Vec which was released in 2013. The idea behind word embedding is to project words into an n-dimensional space where similar words have similar vectors. The size of this space, n, is usually 300-1000. Vector similarity is measured using cosine similarity, dot product or L2 distance. Words are deemed similar if they occur in the same context, i.e. they have similar surrounding words.
For example, “Adam” and “SGD” are often used alongside the same words like “learning rate” and “warmup”. Therefore, their vectors should be similar in the embedding space. This approach enables us to capture similarity between syntactically distant yet semantically similar words (e.g. booking & reservation, Adam & SGD, etc)
These embeddings are utilized by training a task-specific head (e.g. classification, clustering) on top of the frozen embedding; word embeddings are used as fixed input features.
The most common implementations are Wav2Vec (google), GloVe (Stanford), fasttext (facebook).
However, this approach has significant drawbacks: It doesn’t utilize the context of the text. One consequence of this is that words that have the same spelling but completely different meanings (e.g. “bank” in “river bank” and “bank account”) end up with the exact same n-dimensional vector. Furthermore, natural language has nuances that can not be captured just from plain words (sarcasm e.g. “oPeNaI”, intimidation e.g. “skill issue”, “llama3 wen?”)
Beyond words
Word embeddings are too “local”, we need something more “global” that can leverage context to capture higher-level semantics.
However, leveraging more than word-level information from unlabeled text has been challenging.
1. Which objective should we use?
Is it language modeling? Machine translation? Discourse coherence?
We the answer in 2024 where language modeling has dominated NLP, but this paper was published in 2018, even before BERT. Back then, recent research has looked at various objectives with no clear consensus.
2. How to do transfer learning?
That is, how do we actually transfer learned representation to the target task?
Existing techniques involve a combination of the following:
Task-specific changes to the model architecture (e.g. ELMo)
Using intricate learning schemes (e.g. ULMFiT)
Adding auxiliary learning objectives during pre-training
These uncertainties have made it difficult to develop effective semi-supervised learning approaches for language processing.
ULMFiT: A Recipe for SOTA NLP
Jeremy Howard and Sebastian Ruder published a seminal paper in 2018 titled Universal Language Model Fine-tuning for Text Classification (ULMFiT)
The question that motivated this work was: why not pre-train ALL layers instead of just the embedding layer? In computer vision, we take all the layers in a CNN and not just the first layer or two.
They developed ULMFiT: an approach for SOTA text classification.
The recipe is as follows:
Train language model (LM) on general domain data. This is basically pre-training on large corpus in 2024 lingo.
Fine-tune LM on target data. This is continued pre-training on target domain in 2024 lingo
Train classifier on labeled data. This is standard finetuning on target task.
However, the architecture used was an RNN-based model. They did not do any work that utilizes the recent transformer architecture that utilizes self-attention to handle long context dependencies. In fact, there is no mention of the word “transformer” in the paper!
GPT-1: Revolutionizing Natural Language Understanding
In June 2018, just six months after ULMFiT's release, the innovative team at OpenAI, including Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever, introduced the world to GPT-1. GPT stands for Generative Pretrained Transformer, and it revolutionized the field of Natural Language Understanding (NLU).
GPT-1 is a semi-supervised approach designed to excel at a wide range of NLU tasks. The key idea is to learn a universal representation that can be easily adapted to various specific tasks with minimal fine-tuning. To achieve this, GPT-1 employs a two-step process: unsupervised pre-training on a vast corpus of text data, followed by supervised fine-tuning on task-specific datasets.
One of the standout features of GPT-1 is its ability to transfer knowledge across different domains. The target tasks for fine-tuning don't need to be in the same domain as the unlabeled corpus used for pre-training. For example, you can pre-train GPT-1 on a large collection of internet text data and then fine-tune it on internal documentation for a specific task.
The title can be misleading. The “generative” is only for pre-training. Actual tasks are discriminative such as classification and semantic similarity); they are natural language understanding (NLU) tasks
This work was published in a blog post with a more suiting title: Improving language understanding with unsupervised learning
Related Work
1. Semi-supervised Learning
GPT falls under semi-supervised learning for NLP, a growing area of research. This approach has been applied to tasks like sequence labeling and text classification, leveraging both labeled and unlabeled data.
There are different levels of sophistication in semi-supervised NLP:
Level 1: Linguistical statistics (e.g. TF-IDF, Bag of Words) are used as input features, capturing limited semantic information.
Level 2: Word embeddings (e.g. Word2Vec, GloVe) are used, capturing nuanced semantic relationships between words, but still limited to word-level information.
Level 3: Sequence embeddings, trained on unlabeled corpora, capture contextual relationships and higher-level semantics, allowing for a deeper understanding of natural language.
2. Unsupervised Learning
Unsupervised pre-training, a special case of semi-supervised learning, has emerged as a powerful technique in deep learning. The goal of unsupervised pre-training is not to modify the supervised learning objective, but rather to find a good initialization point for the model. This approach has been explored in various domains, including computer vision, where pre-trained models like ResNet on ImageNet are commonly used as backbones for target tasks like object detection.
Research has demonstrated that unsupervised pre-training acts as a regularization scheme, leading to better generalization in deep neural networks. In the context of natural language processing, pre-training a neural network using a language modeling objective and then fine-tuning it on a target task with supervision has shown promising results. For instance, Dai et al. and Howard and Ruder have successfully applied this method to improve text classification using RNNs.
However, one limitation of using RNN-based models is that they restrict the prediction ability to a short range. To overcome this limitation, alternative approaches have been proposed, such as using hidden representations from pre-trained language or machine translation models as auxiliary features while training a supervised model on the target task. While these approaches have shown promise, they often require a substantial amount of new parameters for each separate task, which can be computationally expensive and inefficient.
The GPT Recipe
The authors suggested a simple 2-step recipe:
Unsupervised pre-training on a large corpus
Supervised finetuning on a target domain
1. Unsupervised Pre-training
In this step, we train a high-capacity foundational model on a large corpus of text to obtain a good understanding of natural language.
The learning objective is language modeling, i.e. predict the next token given a sequence of input tokens.
The loss function used is negative log-likelihood, aka crossentropy. It has the following formula:
where k is the size of the context window, and the conditional probability P is modeled using a neural network with parameters Θ.
Tokenizer
They used a BytePair Encoding (BPE) tokenizer with a vocabulary size of 40,000 tokens.
Architecture

They utilized a multi-layer decoder-only transformer. It is very similar to the original transformer architecture presented in Attention is All You Need with the following modification:
Only using the decoder without cross-attention to the encoder
Using learned positional embedding instead of sinusoidal embedding
It has 12 decoder blocks transformer with masked self-attention heads with 117M parameters.
Embedding
Learned positional embeddings
Max context length: 512 tokens
Tied input and output token embeddings
Attention
number of attention heads is 12
64-dimensional states each (for a total of 768).
MLP
Position-wise feed-forward network
Size of inner state: 3072
Activation: GELU
Forward Pass
Add the positional embedding vector and the token embedding vector
\(h_0 = UW_e + W_p\)For N layers:
Apply multiheaded masked self attention
Pass the output through a position-wise feedforward network
\(h_1 = \text{transformer\_block}(h_{l-1})\quad Vi \in [1, n]\)Use the output head to project hidden states into a probability distribution over the vocabulary tokens
\(P(u) = \text{softmax}(h_nW_e^T)\)
We use tied input-output token embedding (i.e. the same embedding layer for input and output)
2. Supervised Fine-tuning
For the finetuning step, we adapt the parameters of the pre-trained model to the supervised target task.
We need a labeled dataset C, where each instance consists of a pair of sequence of input tokens and a label ([x1 , . . . , xm], y).
The inputs are passed through our pre-trained model to obtain the final transformer block’s activation hlm
This is then fed into an added output head with parameters Wy to predict y:
This gives us the following loss function to minimize
The only additional parameters required for finetuning are Wy (the new head) as well as embeddings for new delimiter tokens.
Auxiliary Learning Objective
In the finetuning stage, they used language modeling as an auxiliary objective.
This helped learning by
Improving generalization of the supervised model.
Accelerating convergence.
This is in line with prior work, which also observed improved performance with
such an auxiliary objective. Specifically, we optimize the following objective (with weight λ):
Auxiliary learning objectives are mostly NOT used in training LLMs in 2024
3. Multitask Capabilities
GPT-1 is not just a classifier; it should be able to handle multiple tasks such as entailment, semantic similarity, and multiple choice question answering.
For some tasks like sequence classification, we can directly fine-tune the model as described previously. Other tasks, however, have structured inputs.
For example, text entailment has ordered sentence pairs while multiple choice questions answering have triplets of document, question, and answers.
Previous work proposed learning task specific architectures on top of transferred representations. This re-introduces a significant amount of task-specific customization, and it doesn’t use transfer learning for these additional architectural components.
Instead, we use a traversal-style approach: convert structured inputs into an ordered sequence that our pre-trained model can process. These input transformations allow us to avoid making extensive changes to the architecture across tasks. All transformations include adding randomly initialized start and end tokens (<s>, <e>).
4. Task-specific Transformations
Textual entailment
This task involves reading a pair of sentences and judging the relationship between them. The relationship is one of entailment, contradiction or neutral.
It remains challenging due to the presence of a wide variety of phenomena like lexical entailment, coreference, and lexical and syntactic ambiguity.
Transformation
Concatenate the premise P and hypothesis H token sequences with a delimiter token ($) in between.

Semantic Similarity
This task involves predicting whether two sentences are semantically equivalent or not. There is no inherent ordering of the two sentences being compared.
The challenges lie in recognizing rephrasing of concepts, understanding negation, and handling syntactic ambiguity.
Transformation
We use a siamese architecture and modify the input sequence to contain both possible sentence orderings (with a delimiter in between) and process each independently to produce two sequence representations.

Multiple Choice Question Answering
For theis task, we are given a context document z, a question q, and a set of possible answers {a1, a2, … , ak}.
Transformation
We concatenate the document, context and question with each possible answer, adding a delimiter token in between to get our input sequence [z; q; $; ak].
Each of these sequences are processed independently with our model and then normalized via a softmax layer to produce an output distribution over possible answers.

Model Training
1. Unsupervised Pretraining
Dataset
We use the BooksCorpus dataset for training the language model. It consitis of over 7,000 unique unpublished books from a variety of genres including adventure, fantasy and romance.
It contains long stretches of contiguous text; this allows the generative model to learn to condition on long-range information.
An alternative dataset, the 1B Word Benchmark, which is used by ELMo is approximately the same size but is shuffled at a sentence level - destroying long-range structure.
The trained model achieves a very low token level perplexity of 18.4 on this corpus. (Not so low in 2024!)
Optimizer
We use the Adam optimizer with the following:
b1=0.9, b2=0.999, e=1e-8, l2=0, vector_l2=False, max_grad_norm=-1
Max learning rate: 2.5e-4
Warmup: Linearly from 0 to max_learning_rate over 2k steps
Schedule: Cosine anneal from max_learning_rate to 0 over the remaining steps
These numbers are very familiar as we used very similar values for training LLMs in 2024!
2. Supervised Finetuning
Dataset
We utilize annotated datasets for the following tasks:
Natural language inference
Question answering
Semantic similarity
Sequence Classification
Optimizer
We also use the Adam optimizer with the following:
Learning rate: 6.25e-5
Number of training epochs: 3
batch size: 32
warmup: over 0.2% of the training
Schedule: Linear decay
Weight of auxiliary learning objective (λ): 0.5
These numbers are very familiar as we used very similar values for training LLMs in 2024!
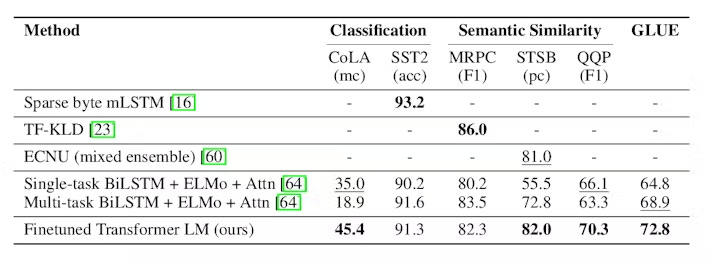
SOTA Results
The finetuned GPT-1 model achieves state-of-the-art results on various benchmarks as shown below
Natural Language Inference

Question Answering & Common Sense

Semantic Similarity & Classification
Analysis
All layers are important
To study the effect of transfer learning, the authors experimented with varying the numbers of layers transfered from the pre-trained model to the finetuned model and evaluated the resulting models.
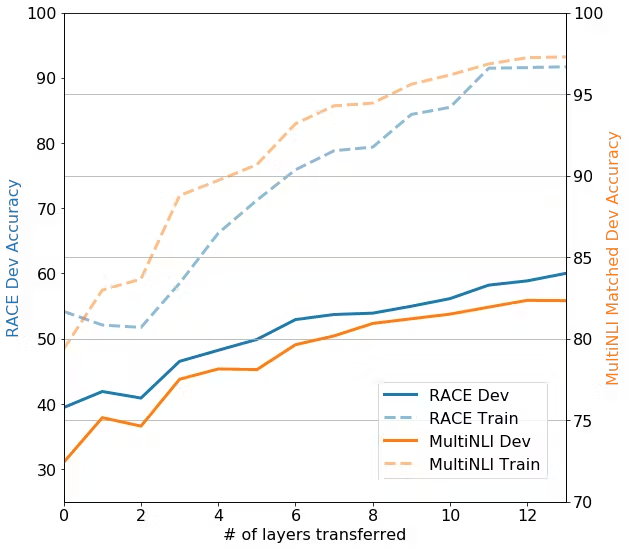
We notice a very strong positive correlation between the number of layers tranfered and the accuracy on downstream tasks. Notably, transfering only the embedding layers still improves performance. Each additional layer transfered adds 9% on MultiNLI.
Zeroshot Capabilities
So far, it is obvious that pre-training transformers as language model is very effective. The authors hypothesize this is because of two points:
The underlying generative model learns to perform many of the
tasks we evaluate on in order to improve its language modeling capability
The more structured attention memory of the transformer assists in transfer compared to RNNs.
To test out this hypothesis, they designed a series of heuristic solutions that use the pre-trained model to perform tasks without supervised finetuning, i.e. zeroshot inference.
An example of this is as applied to SST-2 (sentiment analysis), where we append the token “very” to each example and restrict the language model’s output distribution to only the words “positive” and “negative”. We select the token it assigns higher probability to as the prediction. They developed heuristics for other tasks like sentiment analysis and question answering.
These heuristics are used to evaluate the model during pre-training. They report the results in the following chart
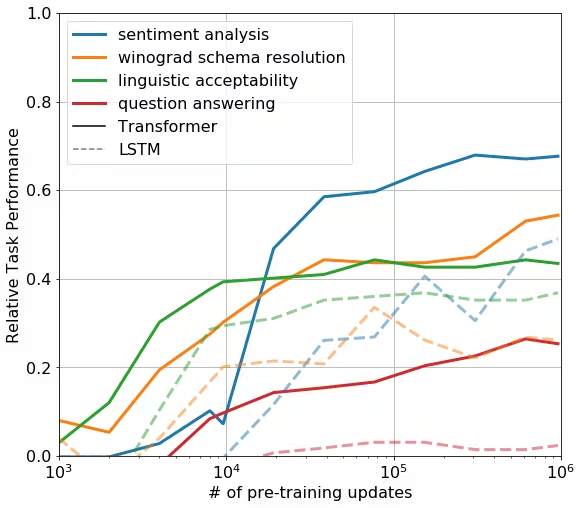
We observe a steady increase in performance over training. This confirms our hypothesis that language model pre-training supports the learning of a wide variety of task relevant functionality. Another conclusion is that the attention memory of transformers exhibits stronger performance compared to RNNs
Ablation
The authors carried out ablation studies to see the effect of:
Language model pretraining
Transformer architecture
Auxiliary learning objective
Auxiliary Learning Objective is a hit and miss
To see the effect of pre-training, the authors dev a gpt-1 without an auxiliary language modeling during finetuning (row 3) and compared its performance with the standard gpt-1 (row 1)
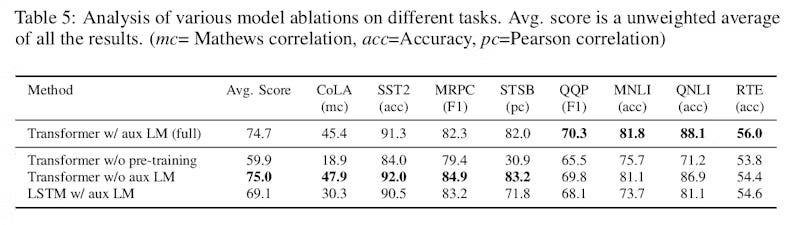
They obtained mixed results where auxiliary LM boosts performance in some tasks and hurts it on other tasks. Its effect is also very small.
Transformers are better LMs
To see the effect of architecture, the authors trained an LSTM (row 4) and compared its performance with the standard gpt-1 (row 1)
The results show noticeably decline in performance when we switch to the LSTM model. This idicates the superior performance of pre-trained transformers compared to LSTMs.
Lnaguage model pre-training is crucial
To see the effect of pre-training, the authors trained a gpt-1 directly on the target tasks without any pretraining (row 2) and compared its performance with the standard gpt-1 (row 1)
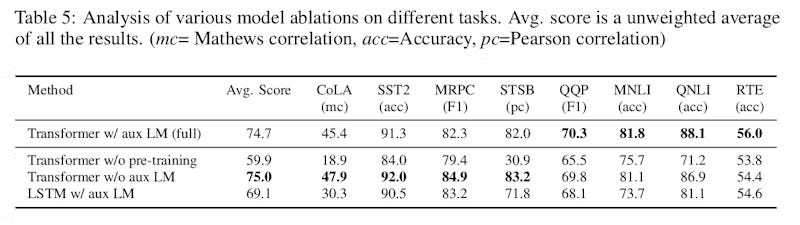
Removing the pre-training step has by far the most signifcant drop in performance. This clearly indicates the importance of pre-training to obtain SOTA performace.
Recap
The authors introduced a framework for achieving strong natural language understanding with a single task-agnostic model through generative pre-training and discriminative fine-tuning. They improve the state of the art on 9 of the 12 datasets they study.
By pre-training on a diverse corpus with long stretches of contiguous text, the model acquires significant world knowledge and ability to process long-range dependencies. These are then successfully transferred to solving discriminative tasks such as question answering, semantic similarity assessment, entailment determination, and text classification.
Using unsupervised (pre-)training to boost performance on discriminative tasks has long been an important goal of Machine Learning research; their work suggests that achieving significant performance gains is indeed possible, and offers hints as to what models (Transformers) and data sets (text with long range dependencies) work best with this approach.
If you liked this post, feel free to like it, share it in your network and subscribe to my blog. Additionally, if you need help building and shipping AI-powered products and services, consider hiring me
Extras
These are some things I found interesting while researching GPT-1. They aren’t directly relevant to the research done but I found them insightful
Visualizing GPT-1’s Positonal Embeddings
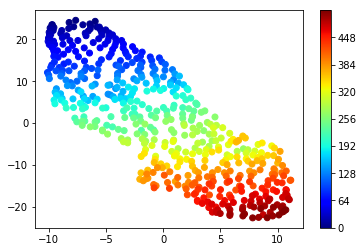
These are the positional embedding vectors when reduced into 2D using t-SNE
The color indicates the position, ranging from dark blue for zero up to dark red for 511 which is the maximum position.
As we can see, positions that are closer to each other (e.g. 64 and 65 which have similar colors) have similar vectors (vectors are close to each other). On the other hands, positions that are far apart like 0 and 511 have very distant vectors.
This means that GPT-1 gives similar positional embeddings for tokens that are close to each other in the sequence!
Deep Learning Framework: TensorFlow
While PyTorch is their current choice for a deep learning framework, the OpenAI teams used tensorflow for developing GPT-1. In fact, the code released for GPT-1 is still hosted on their github repo
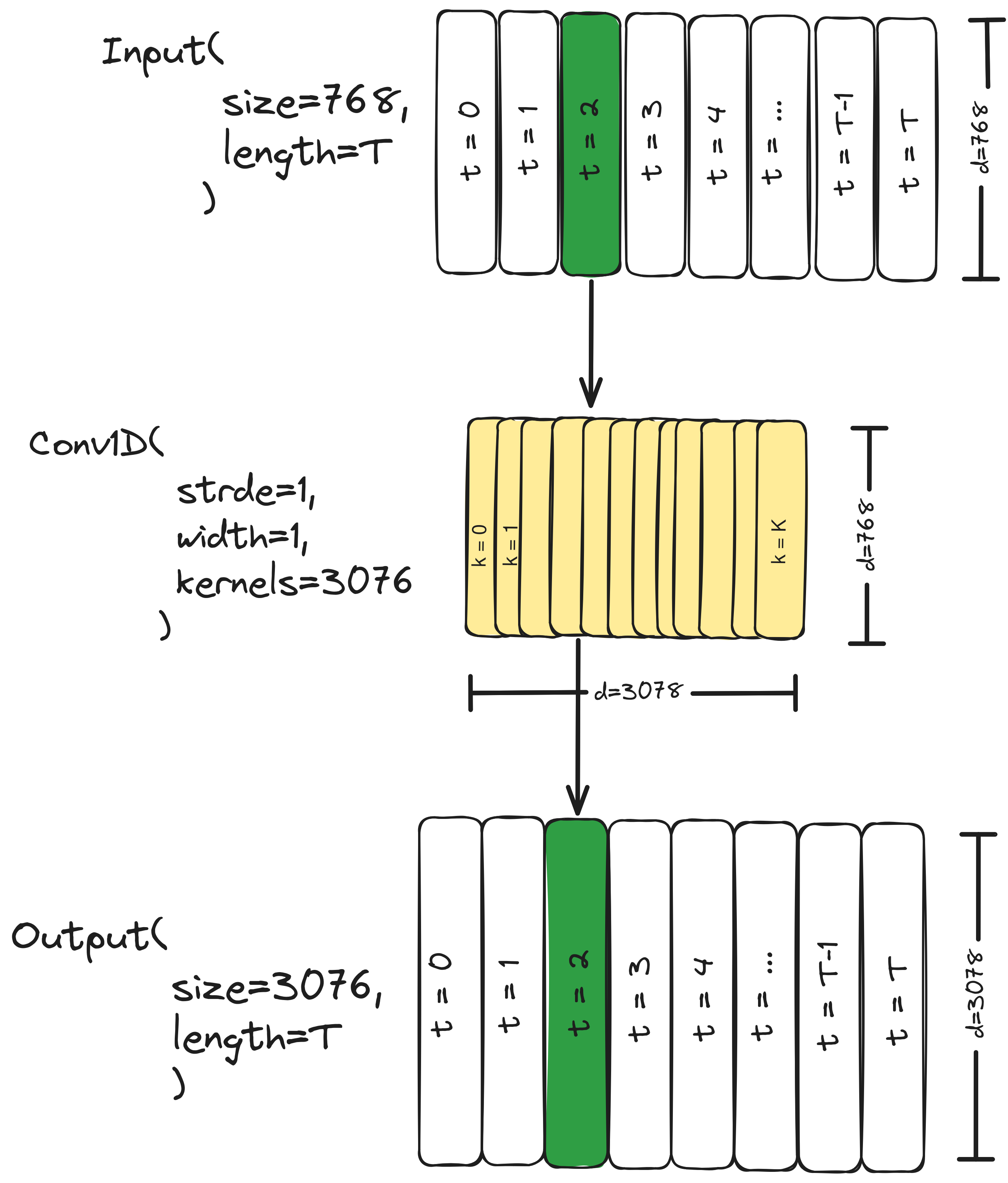
Use of Convolutions
The actual implementation of GPT-1’s uses 1d-convolutional layers. For the position-wise feedforward layer, they use a Conv1D(stride=1, size=1) alongisde the time dimension. This is the same as using a position-wise feedforward layer:
INNER_SIZE = 3072
EMEDDING_SIZE = 768
feedforward1 = Conv1D(stride=1, kernels=1, out=INNER_SIZE)
feedforward2 = Conv1D(stride=1, kernels=1, out=EMEDDING_SIZE)
inner_states = feedforward1(attention_output)
hidden_states = feedforward2(inner_state)