
Explaining how LLMs work in 7 levels of abstraction

Overview
Large language models (LLMs) have taken the world by storm. A few years ago, they were a niche that had the interest of machine learning researchers in big AI labs. Today, almost everyone is using them from software engineers to artists and writers to the average Joe.
Although they are widely used, they are poorly understood by the vast majority of their users. In this blog posts, I aim to intuitively explain how LLMs work. We will start from a very high level of abstraction and go deeper and deeper, revealing key concepts that are crucial for not only understanding the underlying principle of language modeling, but also for harnessing their full potential.
By the end of this post, I hope you will become a much better LLM user who can get these models to generate accurate responses to whatever task you throw at them, by analyzing your data and applying the principles discussed.
Let’s get started!
1. LLMs are assistants
LLMs such as OpenAI’s ChatGPT and Claude are AI-powered assistants. Given a query or instruction (called a prompt), they generate a response targeted at this input. They are often helpful and supportive which makes them great for explaining new concept to newcomers without being judged (ahem Stack Overflow!)

They are also good at summarizing long blog posts, proofreading drafts and rewriting text in a certain style or language and many, many other tasks.
2. LLMs are fancy autocomplete systems
When we dive deeper beyond the “assistant” abstraction, we discover that LLMs are fancy autocomplete systems.
When provided with a text prompt, an LLM continuously generates the next word in an auto-regressive manner. This means that the word just generated by the model is added to the existing prompt to form a new prompt, which is then used to predict the next word, and so on.

While they are conceptually similar to the autocomplete systems we have had in keyboards for a decade, they are much more capable (and also more expensive to run) and are significantly better at predicting the next word accurately.
This is because they are trained on massive datasets that are tens of trillions of words in size. For reference, Wikipedia has around 5 billion words.
Here is a sample of the data used to train these models.
Two coaxial solenoids each 30.0 cm long, carry current I = 3.00 A, but in opposite directions, as shown in Fig-5. The inner solenoid of radius a1 = 3.00 cm has n1 = 15 turns/cm, and the outer one of radius a2 = 6.00 cm has n2 = 30 turns/cm. Find the magnitude and direction of the magnetic field, B, a) Inside the inner solenoid, b) Between the inner and outer solenoids, c) Outside the outer-most solenoid. d) What’s the inductance of the inner solenoid? e) What’s the inductance of the outer solenoid?
The model trained on such data is called a base model. It just autocompletes the text that is given in the prompt.

So how do we make LLMs helpful assistants? Let’s see in the next section!
3. LLMs require instruction tuning
Modern base LLMs are very capable but are difficult to steer or control. This is where instruction tuning comes in.
Instruction tuning teaches the model to generate an output that follows the instructions given by the user. But we first need to differentiate between the user input from the model’s response. This is done by using special keywords which are defined by a prompt template, also known as instruction / chat template.

Notice the special key word <|im_end|>. It is known as the stop word or stop token. The model is trained to generate this stop word when it has completed the response. At inference time (i.e. when we actually use the LLM), when we get this key word as the generated word, we know the model has finished generating the response and we stop the generation process (i.e. appending the new word and sending the new prompt to the model).
Most models are trained using a single prompt template, like OpenAI's ChatML or Mistral's specific format. Since models are fine-tuned with only one template, using that template correctly is crucial for accurate responses. If you provide input in a different format, the model may default to simple text prediction instead of following instructions, as it wasn't trained to interpret other templates.
Tip: Always double check your model is receiving input in the correct prompt format. An extra space or newline can make the output significantly worse
4. LLMs generate probabilities, not words
LLMs don't directly output the next word; instead, they generate a probability distribution for the next word over a predefined vocabulary.
A typical vocabulary might contain around 128,000 words.

So how do we get words from LLMs? Well, LLMs give us a probability distribution and it is our job to sample from this distribution. Sampling is simply selecting one word from all the possible words in the vocabulary based on a chosen strategy.
The most obvious strategy is to always pick the word with the highest probability; this is known as greedy sampling. It is greedy because we pick the most probable word at each step without considering next steps, we’re being greedy!
There are various sampling strategies, each with parameters like temperature, top-p, and top-k, that significantly impact the quality of the output.
Sampling is a very important topic in LLMs and can significantly affect the quality of the output. Tasks like reasoning and coding require more deterministic output which is achieved by having a lower temperature such as 0 or 0.2. On the other hand, role playing and creative writing requires diverse and novel output which is achieved by higher temperature such as 0.8 or 1.
If you’re interested in a blog post about sampling, let me know and I might write one!
5. LLMs operate on tokens, not words
While we've discussed LLMs as though they operate on words, that's not entirely accurate. In reality, any text input to an LLM is first tokenized by a tokenizer. This process converts the text (or "string" in programming terms) into a sequence of discrete tokens.
In most modern LLMs, tokens are often words or sub-words. These tokens are pre-defined ahead of training and used to build the vocabulary that will be used by the model to generate probability distributions.

Once a models has been trained, we can NOT change the tokenization method or the vocabulary on the spot. We will have to train the model again so that it adapts to the new tokenization method and the new vocabulary.
6. LLMs operate on token ids
LLMs actually don’t operate on “tokens”. They are based on artificial neural networks (ANNs) and these can only process numbers (integers and fractions or floats); they don’t quite understand text or strings.
This is why after tokenizing text, we encode the discrete tokens into integers known as token ids. This process is also handled by the tokenizer which uses the positions of tokens in the vocabulary as ids

Take a look at qwen-2-7b vocabulary to get a better idea.
Why is this important?
LLMs receive their input in the form of sequence of integers. A small change in the text that may not be perceived by humans can result in a completely different sequence of integers, which means a completely different input that may get mapped to a different output.

This also explains why LLMs struggle with simple tasks such as counting the number of “R”s in the word strawberry or reversing a word.
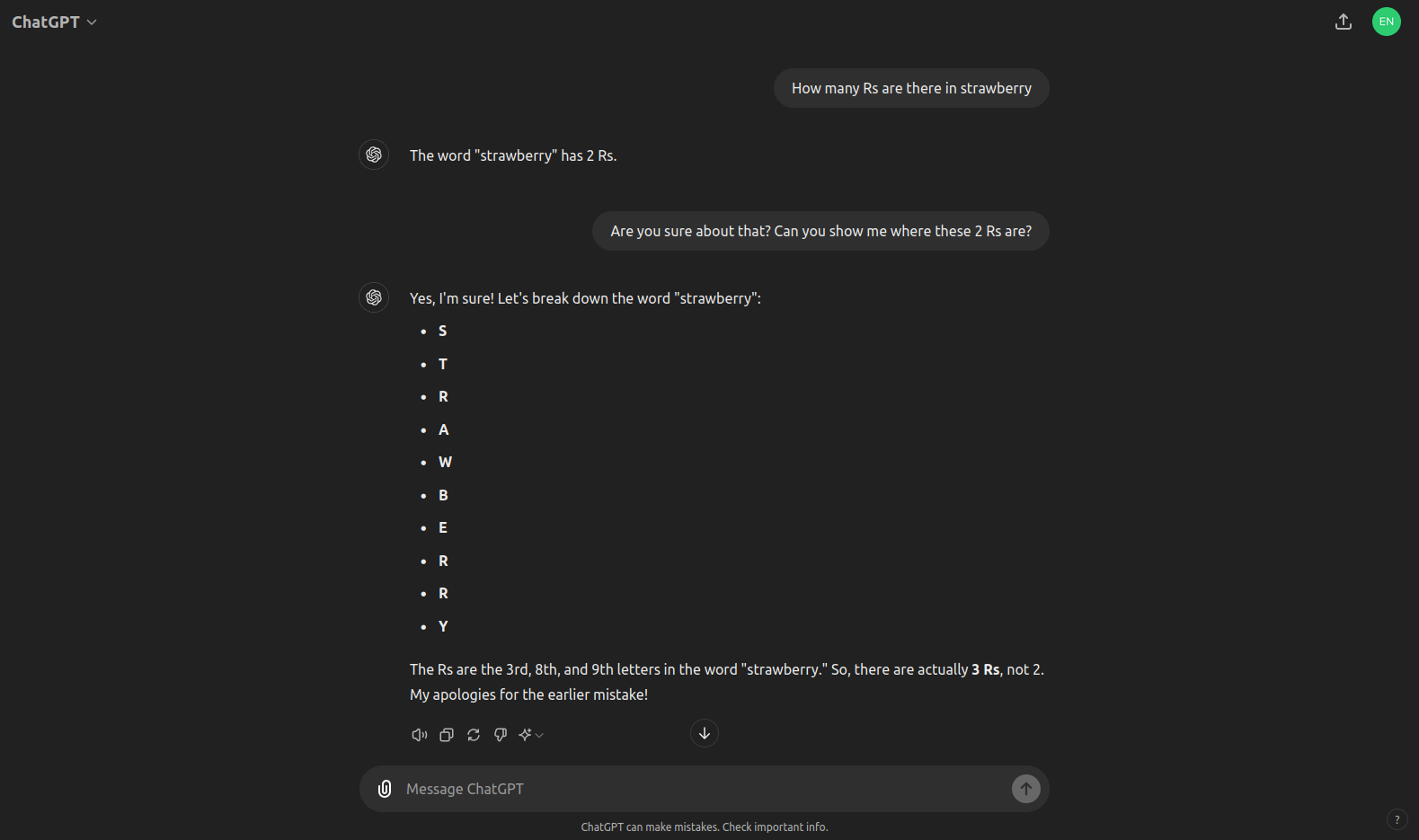
This becomes less surprising when we analyze the tokens and see that strawberry is only one token with a token id equal to 73700, which is very different from the token id of the letter R which is 19766. If we ask the model to break down the word and locate the letter R, it does a much better job as it now can clearly see there are 3 Rs.

Another example is reversing the word “copenhagen”, without capitalization.

This is because “copenhagen” is tokenized into two tokens, which the model is probably not used to seeing.

However, it can reverse “Copenhagen” when it’s capitalized.

This is because it is tokenized properly into one word which has probably been seen a lot by the model in the training data.

Tip: Make sure to look at your data and the raw integer ids sent to the LLM, not just the text that is in the input. Tokenization issues could be the only thing stopping you from getting the correct output.
7. Transformers operate on vectors, not integers
While LLMs operate on token ids that are generated by the tokenizer, the transformer (which is the core of the LLM) actually expects a sequence of multi-dimensional vectors. This is where embedding comes in.
The embedding block is the first block in an LLM and it is responsible for converting the sequence of integers into a sequence of vectors. This is done by projecting each integer id into a multi-dimensional vector. This dimension is known as the embedding dimension. Tokens are projected into a space such that similar tokens (i.e. tokens with similar meaning such as “booking” and “reservation”) have similar vectors (i.e. vectors that are close in the embedding space as measured by the dot product or cosine similarity).
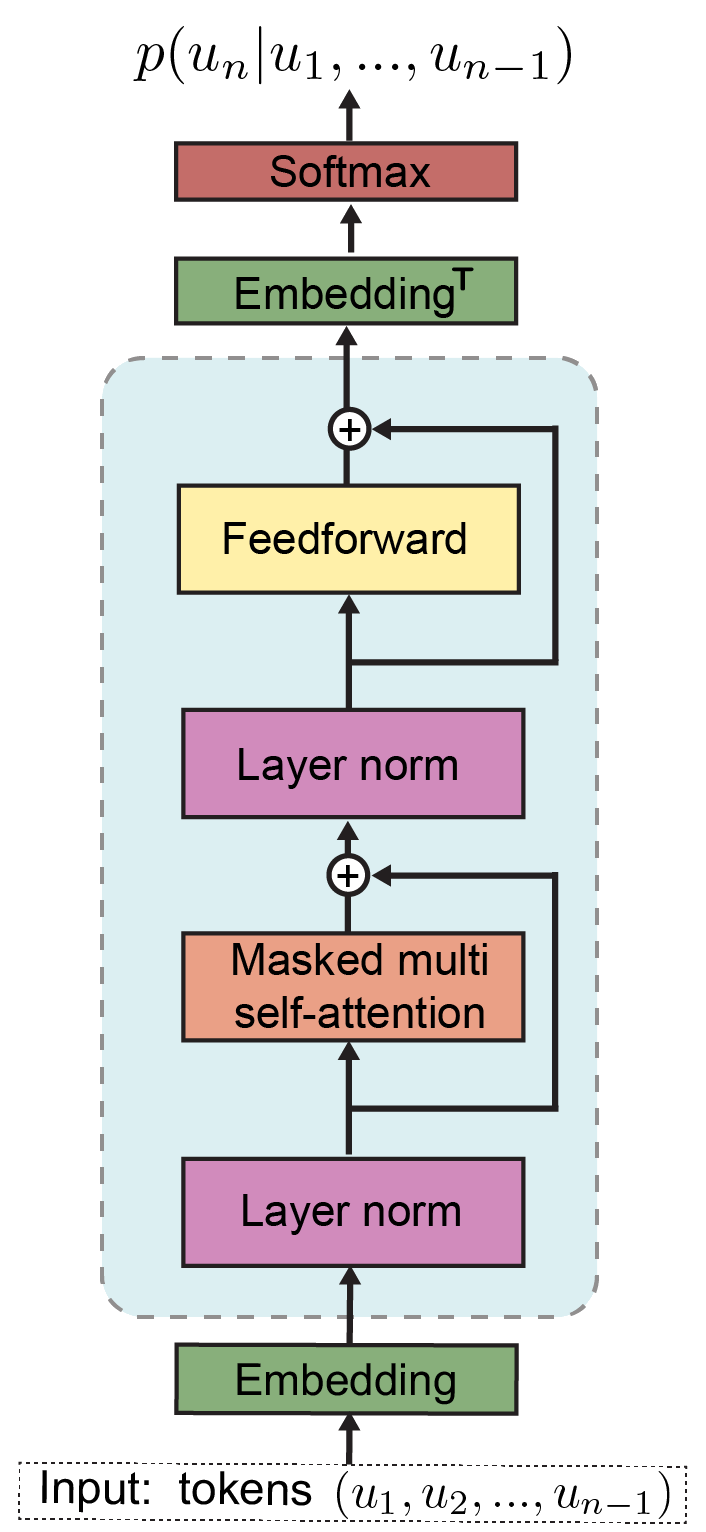

In addition to the token embedding layer, there is also the position embedding layer which encodes information about the position of each token relative to other tokens. This position embedding layer often have the max position hard coded, which means that exceeding this maximum position (by feeding the LLM longer text than it supports) results in incoherent and unexpected output.
Recap
Here is a summary of how LLMs work:
We format our query in the correct instruction template. This query is then tokenizaed and encoded into a sequence of token IDs. This sequence is sent to the model which will generate a probability distribution conditioned on this sequence. We sample one token out of this distribution and append it to the existing sequence of token IDs to create a new prompt, which will then be used to generate the next token. We do this until the model decides that it has finished generating the response and outputs the stop token.
We've journeyed from the seemingly simple concept of an AI assistant to the intricate mechanics of tokenization and embedding. While the surface of LLMs might appear deceptively smooth, the underlying complexity is profound. By understanding these fundamental building blocks, you've gained a powerful toolkit to harness the potential of these extraordinary models.
Remember, LLMs are tools, and like any tool, their effectiveness depends on the user's knowledge. With a deeper comprehension of how they function, you can refine your prompts, anticipate potential pitfalls, and most importantly know how to debug them.
Thank you for taking the time to read this post.
If you have any questions, please leave a comment below.
Concerning hardware resources, is the LLM process MIPS or FLOPS intensive – the article implies both, maybe?