
Demystifying OpenAI's new Whisper Turbo
Delving into how the model was trained, its limitation and how it compares to faster whisper and distill whisper

Overview
OpenAI has just released a new version of whisper a few days ago. The new model, named Whisper Large V3 Turbo, or Whisper Turbo for short, is as a faster and more efficient version of the large v3 whisper model with minimal degradation in accuracy.
While there is no paper and not much info to present, I found that some people are a bit confused about the new model, so I thought I could write something to explain things a bit.
What is Whisper?
Whisper is a state-of-the art machine learning model for automatic speech recognition (ASR). It supports many tasks such as speech transcription, speech translation and voice activity detection (VAD). The architecture is based on an encoder-decoder transformer, very similar to the one presented in the Attention is All You Need paper.
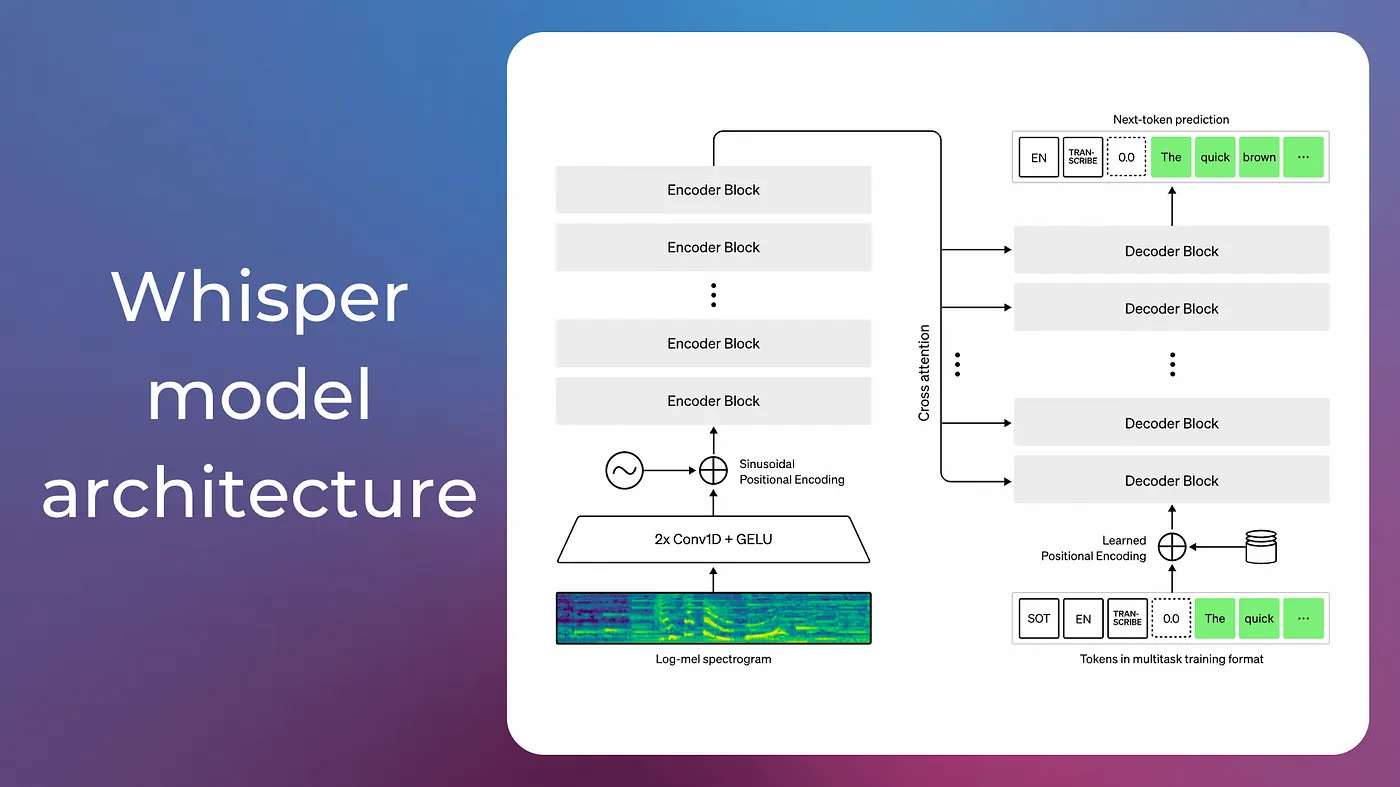
I’ve covered Whisper’s architecture and how it actually converts audio into text in details in a separate post here. Check it out to get a deeper understanding.
The original release (and the subsequent large-v2 and large-v3 models) featured multiple sizes as shown in the table below, but they all shared a common feature: the number of encoder layers is equal to the number of decoder layers. For example, the original whisper large v3 has 32 encoder layers and 32 decoder layers.
Motivation: Distill Whisper
Whisper Turbo was inspired by the work behind Distill Whisper, which in turn was inspired by the following observations:
The decoder is responsible for 90% of the inference time (latency) in Whisper.
The decoder performs the ‘simpler’ sub-task in the speech recognition setting of mapping encoder output to text.
The first observation is due to the auto-regressive nature of language models; we generate the output one token at a time, and the newly generated token is used in the input in generating the subsequent token. This means we have to decode each token serially and there is no easy way to parallelize this operation and make use of the batching capabilities of GPUs. On the other hand, we can compute the hidden states of the encoder in parallel since we have the full input sequence already, significantly reducing the latency of the audio processing step when using modern GPUs.
The second observation is based on the performance of the smaller whisper models: they do well when the audio is loud and clear, and suffer significantly when there’s noticeable background noise or the speaker’s audio isn’t clear enough. But they always generate coherent text, indicating the decoder’s ability to model the language; they’re just not able to figure out what’s in the audio.
Maybe we can downsize the decoder significantly to reduce the memory and compute requirements while retaining most of the accuracy?
What is Whisper Turbo?
Whisper Large V3 Turbo is a more efficient version of the original Whisper Large V3 model with minimal degradation. It relies on 2 techniques that allow it to reduce the size of the original model while maintaining most of its accuracy. These are:
Model Pruning
Continued Pre-training
Model Pruning
Model pruning involves eliminating unnecessary parameters from a deep learning neural network to reduce its size and improve inference efficiency. The resulting model has fewer parameters and therefore requires less memory to store and less computations to perform inference.
In the case of Whisper Turbo, all the pruning happened in the decoder. The original model had 32 layers in the decoder, while the Turbo version has only 4. As a result, the Turbo version has 36 (32+4) layers in total compared to 64 (32+32) in the original one; it is ~1.78x smaller!

Continued Pre-training
In the original model, the 32 decoder layers were trained together as a single decoder to produce the corresponding text to the input audio. This training happened over many, many steps (think hundreds of thousands). If we suddenly remove most of them and keep only 4, the resulting decoder won’t be able to produce coherent text, let alone accurate transcriptions. We need some way to adapt these layers to work together as a single decoder.
This is where continued pre-training comes in. In continued pre-training, we train the model further on big amounts of data to teach it new behavior or more knowledge. This is in contrast to fine-tuning, where we train the model further on relatively small amount of data to adjust its behavior slightly or steer it in some direction (like following instruction in the case of instruct and chat LLMs).
In the case of Whisper Turbo, the model was further trained over the same amount of multilingual transcription data used for training large-v3. Translation isn’t included in the training process, so Whisper Turbo isn’t very good at the translation task.1
For reference, the large-v3 model is trained on 1 million hours of weakly labeled audio and 4 million hours of pseudo-labeled audio collected using large-v2. The model was trained for 2.0 epochs over this mixture dataset.2

How does it compare to Distill Whisper?
The Whisper Turbo model is often confused with Distill Whisper. While turbo was inspired by the work of distill whisper of reducing the number of decoder layers, they follow different strategies.
The first difference is in the model size: Whisper Turbo has 4 decoder layers, while Distill Whisper has only 2 decoder layers. They both have 32 encoder layers which they inherit from the original large whisper model. This means Distill Whisper is a little bit faster as it has 2 fewer layers.
The second difference is about the training strategy: Whisper Turbo uses model pruning and continued pre-training which we covered earlier. In this case, all the model layers (encoder and decoder) are trained on the same labeled data as the original model. On the other hand, distill whisper uses knowledge distillation to train the new decoder while keeping the encoder frozen; i.e. the parameters of the encoder aren’t modified.
In knowledge distillation, a smaller and more efficient model is trained on the predictions of a bigger and stronger model; we’re essentially “distilling” or compressing the knowledge and capabilities of the teacher model into the smaller one.

The main limitation of distill whisper is that it was trained on only English audio and therefore isn’t suitable for transcribing other languages. It also wasn’t trained on translation data. just like whisper turbo.
Is it better than faster whisper?
This is a question I’ve seen a lot, but it isn’t a valid question as we’re comparing apples to oranges.
Whisper Turbo is a model version of the Whisper family of models. Other versions include tiny, small, base, large, large-v2, large-v3 (all developed and released by OpenAI) and distill-whisper-v2 and distill-whisper-v3 (all developed and released by HuggingFace based on large-v2 and large-v3 respectively).
On the other hand, faster whisper is an inference engine for whisper models. It is based on the CTranslate2 library, and can be used to run any of the whisper versions we mentioned (and any other version that is fine-tuned, distilled or continually pre-trained from any of these versions with little modification). Other inference engines include OpenAI’s official whisper library, HuggingFace Transformers and whisper.cpp to name a few. These can also be used to run any of the whisper versions we mentioned earlier, but they require a special format and they offer scripts to convert the official checkpoints into their respective formats.
Fine-tuning
Whisper Turbo can be fine-tuned just like any other whisper model. There is an excellent blog post and (with code) from the HuggingFace team that goes into detail about how to fine-tune whisper.
For the hyper-parameters, the author suggests3 starting with a learning rate of 1e-5, but doing a hyper-parameter sweep over multiple learning rate is recommended.
This model is smaller than the original large-v3 model, so it is expected to require less memory and train faster.
Fine-tuning can be used to improve the model’s accuracy over lower resource languages and / or reduce the well-known hallucination problems of whisper.
Need help tailoring Whisper to your specific needs? I've successfully fine-tuned over 14 Whisper models, consistently improving their accuracy and reducing their hallucination on different langauges and domains. Feel free to contact me!"
Benchmarks
This is all great, but how good is the model actually?
Well, the best way is to evaluate it on your own data; different organizations have different needs for languages, domains and speech style.
To get a glimpse about how good or bad this new version is, I’ve evaluated it on 3 long audio files (tens of minutes). These are:
I’ve also evaluated the other versions. Here are the results:

Looks like Turbo is doing pretty well on these audios, and so is distil-large-v3. Large-v3 is a hit and miss: sometimes it’s the most accurate, ant other times it’s one of the worst. distil-large-v2 seems to suffer quite a lot on these files, though.
Recap
In this post, we explored the new Whisper Turbo model and how it was trained. We also compared between it and the work behind distil whisper.
Additionally, we’ve covered finetuning and recommended hyperparameters. Finally, we compared it against the other whisper versions to get an idea about its accuracy.
If you found this post helpful, please share it in your circle and maybe consider subscribing!
And if you have any questions or thoughts, please leave them in a comment below.
You can also check out my contact section if you wanna chat.
Have a nice day!
https://github.com/openai/whisper/discussions/2363
https://github.com/openai/whisper/discussions/1762
https://github.com/openai/whisper/discussions/2363#discussioncomment-10823337
Thank you for this review and the benchmark at the bottom. It seems that Turbo gives the best bang for the buck at the moment. Someone pointed out that OpenAI still recommends Large-v2 in the OpenAI Platform documentation, and your benchmark further supports the view that Large-v2 is slightly more accurate than Turbo, but at a significant speed cost.
https://platform.openai.com/docs/guides/speech-to-text/introduction